
Achtung: Diese Artikelreihe basiert auf Ubuntu Server 18.04. Es existiert eine neuere und komplett überarbeitete Version auf Basis von Ubuntu 20.04 unter:
Übersicht: Ubuntu 20.04 Homeserver/NAS, Teil 1
Dieser Artikel ist Teil der Reihe selbstgebauter Homeserver/Nas mit Ubuntu 18.04
Über die Bedeutung von Backups will ich nicht viele Worte verlieren. Unser Homeserver ist dafür gedacht unsere wichtigsten Daten zu speichern, wie Fotos und Dokumente. Dementsprechend sollte auch für den Fall vorgesorgt werden dass das System ausfällt, oder Dateien versehentlich gelöscht werden. Denn gegen versehentliches löschen hilft auch das beste RAID-System nichts.
In diesem Artikel wird die Einrichtung von zwei verschiedenen Backuplösungen beschrieben. Die Backupsoftware Duplicati wird für ein Cloudbackup eingerichtet. Duplicati lässt sich einfach installieren und anschließend komfortabel über den Webbrowser bedienen.
Außerdem wird ein lokales Backup auf einer externen Festplatte mit Rsnapshot eingerichtet. Rsnapshot ist ein Backuptool für die Kommandozeile und basiert auf der Nutzung von Rsync und Hardlinks. Dies hat den Vorteil, dass die Daten auf der Backupfestplatte von jedem beliebigen LinuxPC wieder gelesen werden können, ohne dass ein spezielles Tool benötigt wird um auf die Daten zugreifen zu können.
Cloudbackup mit Duplicati
Duplicati ist seit vielen Jahren sehr aktiv in der Entwicklung, aber leider gibt es zum derzeitigen Zeitpunkt noch keine finale Version. Allerdings gibt es Beta-Versionen, welche ich seit längerer Zeit ohne Probleme einsetze. Die Entwicklung findet in sogenannten experimental-Versionen statt. In unregelmäßigen Abständen wird eine experimentelle Version, die sich als zuverlässig herausgestellt hat, als Betaversion herausgegeben.
Duplicati ist ein Open Source Projekt. Die Projekthomepage ist unter duplicati.com zu finden, der Code steht auf GitHub. Duplicati ist eine sehr vielseitige Backupsoftware, besonders was die Speicherziele angeht. Neben lokalen Datenträgern wie USB-Festplatten werden eine Vielzahl an Cloudspeichern unterstützt. Darunter z.B. Dropbox, Amazon Cloud Drive, Microsoft OneDrive und viele mehr. Außerdem werden Standardprotokolle wie FTP, SFTP, WebDAV uvm. unterstützt, so dass sich eine Vielzahl weiterer Cloudspeicher, oder ein eigener Server als Backend einsetzen lassen.
Die Bedienung von Duplicati erfolgt komfortabel über den Webbrowser
Die Installation von Duplicati
Zuerst wird der Downloadlink für die aktuelle (Beta-)Version für Ubuntu von der Duplicati Downloadseite benötigt. Diese wird via Rechtsklick und „Adresse des Links kopieren“ (je nach Browser unterschiedlich) in die Zwischenablage kopiert. Über die Kommandozeile auf unserem Homeserver laden wir die Datei anschließend herunter.
cd wget https://updates.duplicati.com/beta/duplicati_X.X.X.X-X_all.deb
Das heruntergeladene .deb Installationspaket kann jetzt installiert werden. Da Duplicati in C# geschrieben ist, wird zur Ausführung unter Linux das Mono-Framework benötigt, welches automatisch aus den Ubuntu Paketquellen mitinstalliert wird. Die Installation erfolgt mit
sudo apt install ./duplicati_*.deb
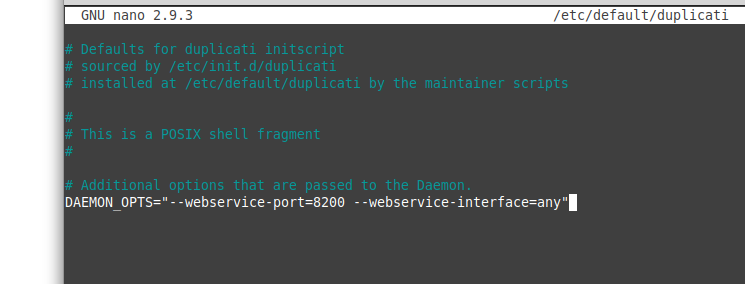
Standardmäßig erlaubt Duplicati den Zugriff auf das Webinterface nur von der selben Maschine aus. Wir wollen aber natürlich von einem beliebigen Computer aus auf das Webinterface zugreifen. Um dies zu ermöglichen muss die Konfigurationsdatei /etc/default/duplicati angepasst werden. Dazu wird diese wieder zuerst mit einem Texteditor geöffnet.
sudo nano /etc/default/duplicati
Dort erweitern wir die Zeile DAEMON_OPTS mit untenstehenden Optionen.
DAEMON_OPTS="--webservice-port=8200 --webservice-interface=any"
Die Konfigurationsdatei sollte danach folgendermaßen aussehen
Jetzt wird der Duplicati-Dienst noch aktiviert, so dass die Software nach einem Neustart automatisch wieder aktiv ist. Außerdem wird Duplicati gestartet, so dass es direkt einsatzbereit ist.
sudo systemctl enable duplicati.service sudo systemctl start duplicati.service
Nun kann Duplicati über den Webbrowser über folgende Adresse aufgerufen werden.
http://192.168.30.114:8200
Die Konfiguration von Duplicati
Zuerst wird man von Duplicati mit einem Sicherheitshinweis konfrontiert. Man kann zuerst ein Passwort für die Benutzeroberfläche festlegen, um zu verhindern dass unbefugte Zugriff auf die Einstellungen und die Backups bekommen. Da die Konfigurationsoberfläche von Duplicati von jedem Computer im Netzwerk erreicht werden kann, ist es sinnvoll hier ein Passwort festzulegen. Dies kann aber auch später in den Einstellungen jederzeit nachgeholt werden.
Die Konfigurationsoberfläche und das Einrichten von Backups mit Duplicati ist selbsterklärend und kinderleicht. Aus diesem Grund verzichte ich auf eine Anleitung zum einrichten des Backups.
Man sollte bei der Einrichtung darauf achten die Ordner /etc sowie /mnt/storage zu sichern. Im ersten liegen die Konfigurationsdateien des Systems, im zweiten unsere Daten. Auch das Sichern des /home Verzeichnisses ist in der Regel sinnvoll.
Außerdem ist es sinnvoll die Konfiguration des Backups z.B. auf einem USB-Stick zu sichern, oder sich diese für den Fall der Fälle per Email zu senden. Damit ist es möglich die Duplicati Konfiguration auf einem neu aufgesetzten System einfach wieder zu importieren.
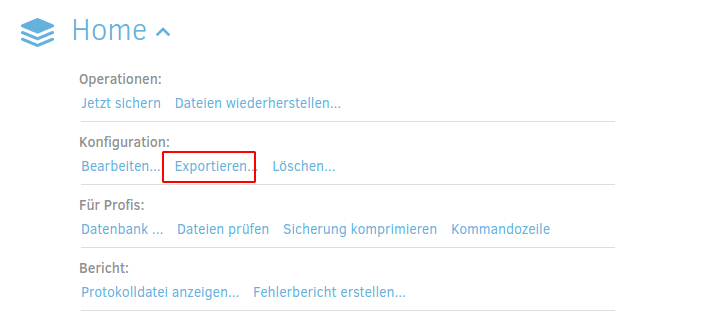
Hierzu klickt man auf den Namen des Backups, in diesem Fall „Home“. Damit klappen weitere Optionen herunter. Hier findet man unter dem Punkt Konfiguration -> Exportieren die Möglichkeit sich alle Einstellungen des Backupjobs „Home“ als Datei herunterzuladen.
Lokales Backup mir Rsnapshot
Rsnapshot ist ein Backuptool für die Kommandozeile welches auf rsync basiert. Rsnapshot erstellt, wie der Name bereits andeutet, sogenannte Snapshot-Ordner auf der externen Festplatte. Dabei wird bei jedem Backup ein neuer Ordner erstellt welcher das Backup enthält, wobei es so aussieht als würde jeder Ordner eine vollständige Kopie der gesicherten Dateien enthalten. Durch die Verwendung von rsync wird eine unveränderte Datei aber nur einmal gesichert. Mit einem Hardlink wird die Datei im folgenden Backup verlinkt, wodurch Speicherplatz gespart wird.
Da es sich trotzdem um normale Dateikopien handelt, können die Sicherungen auf der externen Festplatte von jedem beliebigen PC wieder auslesen. Somit ist sichergestellt dass sich die Dateien auch einfach wiederherstellen lassen.
Rsnapshot lässt sich direkt aus den Ubuntu Paketquellen installieren. Um die USB-Festplatte für die Datensicherung automatisch beim einstecken ins System einzubinden, wird zusätzlich das Programm usbmount installiert.
sudo apt install rsnapshot usbmount
USBMount konfigurieren
Usbmount ist direkt nach der Installation einsatzbereit. Beim einstecken einer USB-Festplatte wird dieses automatisch in /media/usb eingebunden. Steckt man mehrere USB-Laufwerke an, so werden die Einbindungspunkte nummeriert, also /media/usb0, /media/usb1 usw.
Standardmäßig unterstützt usbmount die Dateisysteme vfat ext2 ext3 ext4 und hfsplus. Wenn die Backupfestplatte nur für den Homeserver genutzt wird sollte sie mit dem Dateisystem ext4 formatiert werden, da dies das Standarddateisystem bei Ubuntu ist. Wenn man die Festplatte unbedingt auch auf Windows PCs nutzen möchte und die Festplatte somit NTFS formatiert sein muss, muss dieses Dateisystem in der Konfigurationsdatei von usbmount aktiviert werden.
Dazu wird die Datei /etc/usbmount/usbmount.conf mit dem Texteditor geöffnet und in die Zeile FILESYSTEMS= noch ntfs hinzugefügt, so dass die Zeile folgendermaßen aussieht:
FILESYSTEMS="vfat ext2 ext3 ext4 hfsplus ntfs"

Nun kann die USB-Festplatte eingesteckt und das Backupprogramm Rsnapshot konfiguriert werden.
Rsnapshot konfigurieren
Rsnapshot ist einfach zu Konfigurieren. Die Einstellungen erfolgen über die Konfigurationsdatei in /etc/rsnapshot.conf, welche wieder mit einem Texteditor geöffnet wird.
Wichtig: die Trennung von Schlüssel und Werten, also der Zwischenraum zwischen einer Einstellung und der dahinterstehenden Zahl muss mit der Tabulatortaste [TAB ⇆] erstellt werden. Wenn hier normale Leerzeichen stehen wird die Konfigurationsdatei von Programm nicht akzeptiert und Rsnapshot bricht mit einer Fehlermeldung ab.
sudo nano /etc/rsnapshot.conf
In dieser Datei müssen wenige Einstellungen vorgenommen werden. Im oberen Teil wird unter snapshot_root das Verzeichnis angegeben, in welchem die Sicherungen gespeichert werden. In unserem Fall also /media/usb. Außerdem wird die Einstellung no_create_root von 0 auf 1 gesetzt, damit vor dem Backup überprüft wird ob der angegebene Mountpunkt überhaupt existiert.
########################### # SNAPSHOT ROOT DIRECTORY # ########################### # All snapshots will be stored under this root directory. # snapshot_root /media/usb # If no_create_root is enabled, rsnapshot will not automatically create the # snapshot_root directory. This is particularly useful if you are backing # up to removable media, such as a FireWire or USB drive. # no_create_root 1
Als nächstes werden die Aufbewahrungszeiträume festgelegt. In diesem Beispiel wird jedes Backup der letzten sieben Tage aufbewahrt. Von den einmal pro Woche ausgeführten Backups werden vier aufgehoben und von den Monatlichen sechs. Das aktuellste Backup ist somit von heute, bzw von gestern und das älteste Backup ist ein halbes Jahr alt.
Zuerst suchen wir in der Konfigurationsdatei den Block „Backup Levels„. Die bereits vorhandenen Levels, die mit alpha, beta usw. benannt sind, werden mit einer Raute (#) auskommentiert oder gelöscht. Darunter fügen wir unsere Konfiguration ein, die wir der besseren Übersicht wegen daily, weekly und monthly nennen. Wichtig ist hier wieder die Trennung mittels Tabulatortaste. Der bearbeitete Block sieht dann folgendermaßen aus.
######################################### # BACKUP LEVELS / INTERVALS # # Must be unique and in ascending order # # e.g. alpha, beta, gamma, etc. # ######################################### #retain alpha 6 #retain beta 7 #retain gamma 4 #retain delta 3 #retain hourly 6 retain daily 7 retain weekly 4 retain monthly 6
Im nächsten Schritt wird festgelegt welche Ordner überhaupt gesichert werden sollen. Dies geschieht im Block „Backup Points / Scripts„. In diesem Beispiel werden die Verzeichnisse /home /etc und /mnt/storage gesichert. Mimas gibt den Unterordner auf der der externen Festplatte an unter welchem die Sicherungen gespeichert werden. Das tägliche Backup wird in diesem Fall z.B. unter /media/usb/daily.0/mimas erstellt. Der Backupblock sieht aus wie folgt.
############################### ### BACKUP POINTS / SCRIPTS ### ############################### # LOCALHOST backup /home/ mimas/ backup /etc/ mimas/ backup /mnt/storage/ mimas/
Die Konfigurationsdatei kann nun gespeichert werden. Mit dem folgenden Befehl kann überprüft werden ob die die Datei von Rsnapshot verarbeitet werden kann. Wenn es hier zu einer Fehlermeldung kommt, dann wurde wahrscheinlich an irgendeiner Stelle ein Leerzeichen anstelle von Tab verwendet.
sudo rsnapshot configtest
Aktivieren der Rsnapshot Backups und erstellen des ersten Backups
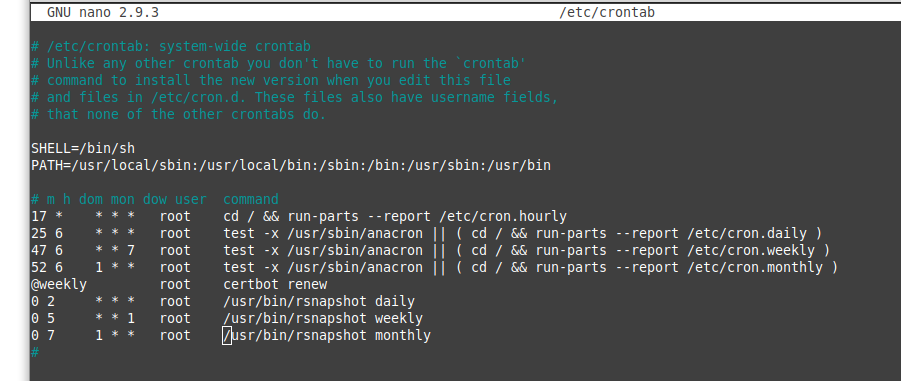
Die Backups werden über einen Cronjob gestartet. Dazu wird die Datei /etc/crontab im Texteditor geöffnet und um folgende Zeilen vor der abschließenden Raute erweitert.
sudo nano /etc/crontab
0 2 * * * root /usr/bin/rsnapshot daily 0 5 * * 1 root /usr/bin/rsnapshot weekly 0 7 1 * * root /usr/bin/rsnapshot monthly
Unsere /etc/crontab sieht mittlerweile so aus.
Die Befehle können auch manuell ausgeführt werden um ein tägliches, wöchentliches oder monatliches Backup auszuführen. Zum Erstellen eines ersten manuellen Backups wird dieser Befehl ausgeführt.
sudo rsnapshot daily
Anschließend sollte sich unter /media/usb ein neuer Ordner mit dem ersten Backup befinden. In den folgenden Tagen werden jeweils neue, durchnummerierte Ordner erstellt. Wer sich für weitere Einstellungen zu Rsnapshot interessiert sollte sich den wie immer hilfreichen Wikieintrag auf ubuntuusers.de durchlesen.
Schluss
Damit steht nun ein vielseitiges und zuverlässiges System bereit, das kommerziellen fertig NAS-Systemen nicht nachsteht. Der Vorteil eines selbstgebauten Homeservers ist, dass sich dieser speziell auf die eigenen Bedürfnisse ausrichten lässt.
Diese Anleitung soll es insbesondere Einsteigern erleichtern ein solches System aufzusetzen und zu betreiben. Die Einsatzmöglichkeiten gehen jedoch viel weiter als in der hier beschriebenen Artikelreihe. So kann beispielsweise mit Tiny-Tiny RSS ein RSS-Reader eingerichtet werden der mit der App auf dem Smartphone synchronisiert wird. Damit hat mein ein komfortables Tool zur Verfügung um sich über das Weltgeschehen und andere Dinge auf dem Laufenden zu halten. Mit Tiny Tiny RSS lassen sich Diesnte wie Feedly oder Inoreader mit einem eigenen System ersetzen.
Oder man installiert sich eine Wallabag Instanz, und ersetzt einen read it later Dienst wie Pocket oder Instapaper.
Ich selbst setze ein ähnlich konfiguriertes System seit vielen Jahren ein und bin sowohl von der Zuverlässigkeit als auch von der Vielseitigkeit begeistert. Ich hoffe dass der eine oder andere Stolperstein aus der alten Version beseitigt ist und vielleicht inspiriert die Artikelreihe den einen oder anderen dazu ebenfalls ein solches oder ähnliches System selbst aufzusetzen.
Homeserver/NAS mit Ubuntu 18.04: Teil 1, Einleitung, Hardware und Kosten
Homeserver/NAS mit Ubuntu 18.04: Teil 2, Systeminstallation
Homeserver/NAS mit Ubuntu 18.04: Teil 3, Grundkonfiguration
Homeserver/NAS mit Ubuntu 18.04: Teil 4, Dateifreigaben im Heimnetz
Homeserver/NAS mit Ubuntu 18.04: Teil 5, Nextcloud
Homeserver/NAS mit Ubuntu 18.04: Teil 6, Media Streaming mit Plex
Homeserver/NAS mit Ubuntu 18.04: Teil 7, Backups mit Duplicati und Rsnapshot
70 Comments
Hi Niko,
super interessantes Tutorial, Dank Dir für die viele Arbeit. Aus welchem Grund ist Open Media Vault o.ä. nicht interessant für Dich?
Grüße, Alex
Ich finde OMV durchaus interessant. Ich habe damit einige Zeit auf einem Raspberry Pi experimentiert. Wenn man mit dem Funktionsumfang von OMV, bzw. den verfügbaren Plugins zufrieden ist, ist das System eine schöne Sache. Mit einem selbstkonfigurierten System hat man halt nicht nur mehr Möglichkeiten, man versteht auch sein System besser, da man dieses selbst aufgesetzt hat. Das ist mir wichtig.
Und noch eine Anschlussfrage: wenn man lieber mit GUI arbeitet, würde sich bei Deinem Setup die Installation von Webmin empfehlen?
Danke.
Ich halte den Einsatz von solchen Tools für höchst fragwürdig. Daher habe ich mich mit Webmin nie näher beschäftigt.
Gruß
Niko
Welche Punkte genau missfallen Dir an Tools wie Webmin?
Man gibt einem Dienst, der über das Internet erreichbar ist, das Recht die Systemkonfiguration zu ändern. Ein Dienst der potentiell voller Sicherheitslücken ist (https://www.cvedetails.com/vulnerability-list/vendor_id-358/Webmin.html). Ubuntu hat aus gutem Grund Webmin aus den Paketquellen entfernt (https://wiki.ubuntuusers.de/Archiv/Webmin/)
Super Tutorial. Mein Ubuntu Server 18.04 rennt. Freue mich schon die ganzen Features zu installieren und zu verwenden.
Endlich ein Server, der das macht, was ich will.
Tausend Dank an dich für die geniale Anleitung.
Eine Frage habe ich aber noch. Hast du mal überlegt, den Gehäuselüfter zu tauschen bzw. abzuklemmen? Damit wäre der Server flüsterleise.
Hast du Erfahrung mit dem Weglassen des Gehäuselüfters?
Wenn es ein neuer Gehäuselüfter sein soll, welchen würdest empfehlen?
Vielen Dank im Voraus.
Sven
Freut mich dass es gut läuft.
Ich habe den Gehäuselüfter tatsächlich getauscht und einen manuellen Drehregler eingebaut um die Drehzahl zu reduzieren. Kann dir da leider keinen Tipp geben. Das waren Teile die ich in irgendeiner Schublade hatte.
Gruß
Niko
Hallo
Vielen dank für das super tutorial.
Hast du eine Idee wie ich am besten noch einen service installieren das system in idle setzt und die Festplatten zB austauscht ?
Falls du hier einen Tipp hast wäre ich sehr dankbar
Gruss
Marcel
verstehe leider nicht ganz was du damit meinst. Wenn du eine Festplatte tauschen möchtest, kannst du das System doch herunterfahren?
Gruß
Niko
Hallo Niko,
es geht darum dass das System in idle geht sobald jmd zb.die nextcloud app nutzt etc oder ich von meinem desktop aus auf die festplatten per netzwerk zugreife.
Das geht soweit ich weis mit dem Wakeonlan und das ist noch nicht in dem System automatisch konfiguriert und ich wollte fragen ob du weißt wie dies geht?
Gruß Marcel
Ah, verstehe. Ja, mit einem Wake-on-LAN-Paket lässt sich ein Computer grundsätzlich anschalten, oder aus dem Standby aufwecken. Das wird aber leider nicht so automatisiert und integriert funktionieren wie du das vorhast. Mit Wake-on-LAN schickst du ein spezielles Datenpaket an die Netzwerkkarte, welche dann den Computer aufweckt. Das müsstest du zuerst über eine entsprechende App/Programm auslösen. Dann musst du warten bis das System online ist und dann erst kannst du die Nextcloud nutzen.
Mir persönlich ist da der Komfortverlust zu groß. Für eine nur gelegentliche Nutzung ist es evtl. eine Option.
da du so einen Server schon länger betreibst, meinst du man kann den Lüfter auch weglassen? Mein Mainboard und die Platten sind recht kühl.
Ich habe immer einen langsam drehenden Gehäuselüfter eingesetzt. Evtl. geht es auch ohne, muss du ausprobieren. In der Tat sollte das System nicht all zu viel Wärme produzieren.
Hi Niko,
Ich habe vor ein paar Tagen meinen in die Jahre gekommenen Debian-7-Homeserver auf den Stand der Technik gebracht. Dank deiner hervorragenden Anleitung war dies überhaupt kein Problem, auch für weniger Linux-basierte User wie mich! 🙂 Vielen Dank!
Gruß Jörg
Super Tutorial , vielen Dank!
Ein kleiner Fehler auf der Nextcloud-Seite:
in „sudo touch nano /etc/apache2/sites-available/001-nextcloud.conf“ ist wohl ein nano zuviel 😉
Und bei der Plex-Installation kann ich das Verzeichnis nicht komplett verschieben, es kommt ein Fehler und einiges wird nicht verschoben „sudo mv /var/lib/plexmediaserver /mnt/storage“
Gruß
Danke für den Hinweis. Da ist allerdings ein nano zuviel.
Vielleicht klappt das Verschieben nicht richtig weil der Plexserver noch läuft und dadurch bestimmte Dateien blockiert.
Bei mir hat es funktioniert, aber ich werde sicherheitshalber noch einen Befehl in den Artikel einfügen, der den Dienst stoppt und nach dem Verschieben wieder startet.
Vielen lieben Dank für die Mühe uns an deinem Projekt teilhaben zu lassen,
nach langer Suche im Internet übernehme ich deine Liste und baue genau
das Gerät nach. Eine Frage hätte ich noch dazu. Ich möchte eine Plesk Instanz
installieren um mehrere Webseiten sowie service zu hosten, was hälst du von
Home hosting und wie steht es um meine Inet Anbindung? Habe einen 20er Upload
sowie eine feste Ip.
Danke dir und Gruß aus Wiesbaden
Wenn es sich um ein Hobbyprojekt handelt und du Spaß daran hast spricht da sicher nichts dagegen.
Vielleicht noch ein kleiner Hinweis: Ich hatte mir damals einen fertigen HP ProLiant Server für rd. 400,- € (refurbished, inkl. 2x1TB Platten) gekauft und Nikos System mit ein paar kleinen Änderungen darauf installiert. Bin sehr zufrieden und konnte so auf die Bastelei verzichten. Der zieht ca. 28 Watt, ist aber lautstärkemäßig eher was für den Keller. Vielleicht eine Alternative…
Gucke mal in den Energieeinstellungen im BIOS, ob du da die richtigen Belüftungseinstellungen hast… Habe zwar Lenovo, aber bei mir war das auf 4 Festplatten RAID und 2 CPUs eingestellt… Dachte zuerst, dass die Wohnung dann abhebt. Richtig eingestellt war das System dann doch um Häuser leiser!
DAS war mal eine _richtig gute_ Tutorial-Serie! Zwar hatte ich auf dem Plan, einen File-/Media-Server mit Ubuntu 18.04 Server bereitzustellen, wollte aber mit etwas anderem beginnen. Bei der Suche nach Infos dazu bin ich allerdings bei Dir gelandet und habe nun _zuerst_ den Mediaserver an den Start gebracht. Shares laufen, Cloud läuft, Plex läuft (das hat mal direkt für neue Abo-Kosten gesorgt…). Und wie krass: Ich bin zufällig KD Kunde, bzw. nun Vodafone, und habe eine Fritzbox 6490, bei der ich erst vor kurzem bemerkt habe, dass sie DVB-C beherrscht und 4 Tuner eingebaut sind. Und das wird via Plex als Community-Tuner supported! 🙂
Jetzt habe ich noch zwei Themen, die offen sind. Zu einem der beiden Themen kannst Du – fürchte ich – nichts beitragen, denn ich würde mir wünschen, dass Nextcloud auch OneDrive als external Storage unterstützt. Dank Office365 habe ich dort viel Speicherplatz und hätte somit eine zusätzliche Absicherung der Daten.
Thema #2 wäre der Hammer (!) wenn Du dazu auch ein Tutorial veröffentlichen könntest – ich vermute allerdings, dass das nicht passieren wird und das wäre auch verständlich; die Nachfrage nach so etwas ist vermutlich eher gering:
Da hier eh‘ schon Samba zum Einsatz kommt… ich hätte gerne den Server als Domain Controller konfiguriert inkl. Benutzerverwaltung und Gruppenrichtlinien. Und wenn das dann eh‘ schon läuft, ließe sich Nextcloud auch mit der LDAP Integration konfigurieren + die Shares auf dem Fileserver als Homedirectories für die im Netzwerk angemeldeten Benutzer einsetzen.
Bisherige Tutorials, die ich zu dem Thema gefunden habe, sind bei weitem nicht so gut geschrieben, wie das, was Du hier auf die Welt losgelassen hast! Und/oder für veraltete Produkte entworfen…
Zusammengefasst:
Vielen Dank!!! und vielleicht gibt’s ja noch einen zweiten Teil, der dieses Tutorial um DC/LDAP ergänzt. 🙂
P.S.: Einen habe ich noch:
Kennst Du die Microsoft Test Lab Guides (TLG)? Microsoft tut eine Menge dafür, dass Leute ihre Produkte gut ausprobieren können und veröffentlicht dafür u.a. regelmäßig vorkonfigurierte Virtuelle Server mit vorinstallierten Produkten und Guides, die einen durch die Benutzung führen. Sehr cool ist, dass sie eine sehr gute Methodik entwickelt haben, diese Guides zu dokumentieren und auch modular zu gestalten. So etwas fehlt mir in der Linux Welt. Such mal nach Microsoft Test Lab Guides, TLG, Mini TLGs, etc. oder – falls es Dich interessiert – sprich mich mal drauf an.
Hey, das nenne ich mal einen ausführlichen Kommentar. Vielen Dank für die Zeit die Du dir genommen hast und vielen Dank für das Lob.
Ja, OneDrive kann man nicht so einfach in Nextcloud einbinden, ich würde mich auch wundern wenn das kommen würde. Da musst du basteln. Mit Rclone kann man, glaube ich, OneDrive lokal über FUSE mounten. Das könntest Du dann wiederum in Nextcloud einbinden. Habe aber keine Ahnung wie schnell und zuverlässig das ist.
Was Samba als Domain controller angeht ist nicht die fehlende Nachfrage das Problem, sondern eher dass ich dafür einfach keinen Bedarf habe. Für diese Artikelreihe sind tatsächlich einige Wochenenden drauf gegangen. Das kann ich nur für Themen machen, für die ich auch Begeisterung aufbringe.
Die Microsoft Test Lab Guides kenne ich nicht, werde ich mir aber anschauen. Ich nutze gerne die Tools und virtuellen Maschinen, die Microsoft auf modern.ie anbietet. In der Tat tut Microsoft mittlerweile einiges dafür, dass ihre Produkte getestet werden können.
Vielen Dank für die super Anleitung! Der Server funktioniert nun auch bei mir, obwohl ich sonst mit Linux nichts am Hut habe 🙂
Ein paar Anmerkungen/Fragen:
Ich habe erst nach multiplen Neuinstallationen von Ubuntu gemerkt, dass mein Router NAT-Loopback (DynDNS Zugriff aus lokalem Netzwerk) nicht unterstützt. Ich dachte zuerst, es liege an der Installation, dem Port-Forwarding oder dem Switch dazwischen. Deshalb habe ich auch falsche Änderungen am Router gemacht, was mich viel Zeit kostete. Ich würde deshalb hinzufügen, dass der Zugriff über die ddns-Adresse nur dann funktioniert, wenn man entweder von ausserhalb zugreift oder einen passenden Router hat (https://www.datamate.org/nat-loopback-oder-wie-dyndns-fuers-interne-netzwerk-fit-gemacht-werden-kann/). FritzBoxen sollten hierbei meist kein Problem darstellen.
Ich habe meinen Server über http://www.ssllabs.com/ssltest und securityheaders.com getestet. Dabei kommt beide Male nur ein B heraus. Ersteres bemängelt Forward Secrecy und fehlende CAA records (ich benutze no-ip). Securityheaders bemängelt Strict-Transport-Security, Referrer-Policy und Feature-Policy. Ich bin jedoch nicht in der Lage, diese Infos richtig einzuordnen.
Ich habe den Server ursprünglich aufsetzen wollen, um alle meine privaten Belege, Quittungen etc. abzulegen (statt Paperless oder MayanEDMS). Dafür will ich Texterkennung (Tesseract OCR) und Volltextsuche (Solr?) installieren und irgendwie über Cronjobs zum laufen bringen. Ich muss mich aber dort zuerst einmal gründlich einlesen, oder hättest du Lust an einem Tutorial? 😉
Nun bin ich aber auch schon sehr zufrieden an meiner Cloud, welche meine mehreren Festplatten im Desktop ersetzen wird.
Ich habe ein Problem: Wenn ich einen Ordner mit 204GB an Daten in mein Private Verzeichnis über das Netzlaufwerk verschieben will, beklagt sich Windows mit „You need an additional 169 GB to copy these files“. Meine gemountete externe Festplatte ist aber 6TB gross. Ich werde noch einiges ausprobieren, bin aber froh um jede Hilfe.
Vielen Dank für die Info. Mir war tatsächlich nicht klar dass es mit dem NAT-Loopback Probleme geben kann. Fritzboxen machen hier in der Tat keine Probleme. Das ganze Thema DynDNS und Fernzugriff auf das Heimnetz ist eh sehr problematisch für solche Anleitungen. Verschiedene Internetanschlüsse, IPv4/IPv6, DS-Lite, verschiedene Router…
Die Anleitung ist bewusst einsteigerfreundlich geschrieben, weshalb ich auf eine weitergehende Konfiguration des Apache mit eigener Cipher Suite und zusätzlichen HTTP-Headern bewusst verzichtet habe.
Forward Secrecy stärkt die Verschlüsselung natürlich deutlich. Mozilla hat einen schönen Generator erstellt, der die entsprechenden Konfigurationen für den Webserver erstellt https://mozilla.github.io/server-side-tls/ssl-config-generator/. Ansonsten ist https://bettercrypto.org auch eine gute Anlaufstelle.
Einen Strict-Transport-Security-Header und Referrer-Policy kannst Du wahrscheinlich auch relativ gefahrlos setzen. Eine Feature-Policy lässt sich aber nicht einfach anschalten. Natürlich stärken solche Maßnahmen die Sicherheit der verschlüsselten Verbindung. Ein B in einem dieser Test bedeutet aber noch lange nich dass dein System Sicherheitslücken hätte oder generell unsicher wäre.
Ich würde nicht versuchen um jeden Preis eine gute Note bei solchen Tests zu bekommen. Wenn Du dich eingehender mit deinem System beschäftigen möchtest, sind die dort aufgeführten Kritikpunkte natürlich ein guter Anfang.
Woran dein Ordnerproblem liegt kann ich leider auch nicht sagen. Womöglich ist ein temporäres Verzeichnis irgendwo zu klein. Du kannst versuchen nicht den kompletten Ordner auf einmal zu kopieren, sondern kleinere Häppchen von weniger als 35GB (204GB-169GB=35GB)
Hatte das gleiche Problem, bei mir war es, dass ich nicht das Data-Verzeichnis verschoben habe, sondern es auf meiner SD-Karte vom System lag. Nach dem ich es verschoben habe (einfach mal bei Google suchen), konnte ich ohne Probleme alle Dateien hin und her schieben.
Hey Peter,
Danke für die Ergänzung. Das kann auf jeden Fall auch ein Grund sein.
Diese Anleitung habe ich mehrfach getestet. Es ist wirklich wichtig die Schritte einzuhalten, bzw. eventuelle Fehlermeldungen nicht zu ignorieren.
Hallo,
ich möchte Dir für das super Tutorial danken. Ich habe vorher mit Windows Serverversionen rumgespielt die mich aber leider nicht zum selben Ergebnis wie das hier gebracht haben. Das Tutorial macht Lust auf mehr Linux :-).
Großer Dank an die TechGroup!
Endlich mal eine Anleitung die sowohl aktuell als auch gut erklärt ist! Bin seit geraumer Zeit (Intrepid Idex) Ubuntu Desktop Nutzer und habe auch schon so machen Versuch in Richtung ubuntu Server versucht nach Anleitung (eher erfolglos), aber hiermit wird es jetzt gelingen. Eine abgespeckter virtueller Testserver auf VirtualBox läuft schon prima.
Hallo Niko,
vielen Dank für das Update! Ich hatte dein altes Tutorial schon „genossen“ und vieles davon erfolgreich umgesetzt. Entscheidend für einen eigenen Server (statt NAS) war für mich die Möglichkeit, diesen auch als SAT/IP-Server mit TVHeadend zu nutzen. Zum deiner Backupstrategie hätte ich allerdings eine kurze Frage: Du hattest in irgend einem Kommentar zum alten Tutorial mal erwähnt, dass du auf borgbackup umgeschwenkt bist. Hab mir das daraufhin mal angeschaut, für cool befunden und mache meine backups seither erfolgreich mit borg auf dem Strato Hidrive. Gibt es einen Grund dafür, dass du wieder zu Duplicati zurück gekehrt bist?
Hallo Stefan,
für mich ist Borg immer noch das beste Backupprogramm der Welt. Auf dem Desktop habe ich aber immer Duplicati eingesetzt und damit auch sehr gute Erfahrungen gemacht. Da ich diese Artikelreihe bewusst so einsteigerfreundlich wie möglich halten wollte, hielt ich Duplicati einfach für geeigneter.
Hallo Alex,
einfach nur Klasse Dein Tutorial. Ich habe viele Stunden damit verbracht und sehr viel Spass beim Lernen
gehabt. Und es animiert, weiter zu machen!
Hallo zusammen,
Kompliment an das Tutorial, hat mir sehr weiter geholfen und Spaß gemacht.
Bei mir gab es ein Problem, dass trotz USBMount und angeschlossener USB-Platte diese nicht automatisch gemountet wurde (Ubuntu Server 18.04). Den „Fehler“ konnte ich mit folgendem Workaround beheben:
https://www.linuxuprising.com/2019/04/automatically-mount-usb-drives-on.html
Danke und viele Grüße
HI, erstmal dickes LOB.
Das ist mal eine super verständliche und einfache Anleitung.
Leider habe ich an meinem Server rumgespielt und versucht den Jdownloader zu installieren. Hier musste ich die Zugriffsrechte von einem den Storage Ordnern ändern.
Jetzt geht weder mein Jd noch meine Nextcloud.
Da ich inzwischen sowohl maria DB, Nextcloud udn apache mehrfach restlos gelöscht und neu installiert habe und die Berechtigungen zurück gestellt habe gebe ich einen Rettungsversuch auf! Aber bevor ich das Ubuntu neu installiere würde ich gerne wissen ob ich auf meine StorageFestplatten danach einfach zugreifen kann?! Oder sollte ich versuchen alle daten auf externe HDD’S auszulagern und dann frisch von vorne beginnen?!
Dein Storage-Raid kannst du jederzeit auch wieder in eine neue Ubuntu Installation einbinden. Allerdings passiert das zumindest bei der Serverversion nicht automatisch, das musst du von Hand machen.
An deiner Stelle würde ich die Daten zusätzlich auf einer externen Festplatte speichern. Sicher ist sicher.
Alles klar, genauso werde ich es machen! Vielen Dank! Sowohl für die Antwort als auch für diese wirklich gute Tutorial!
Danke für die tolle Artikelreihe – ohne die wäre es deutlich schwieriger gewesen, meine neue NAS aufzusetzen.
Eine Frage zu Backup, v.a. wegen der Geschwindigkeit: Ich lasse das Backup mit rsnapshot auf eine USB-Festplatte laufen. Das sind dann ca. 2TB Daten (viele Fotos) vom Raid-Storage.
Gestartet hab ich den ersten Durchlauf vor 2 Tagen. Von den 2TB sind inzwischen gerade mal 365GB übertragen. Ich finde das unglaublich langsam. Hätte für den ersten Durchlauf so mit maximal 2 Tagen gerechnet. Sind das evtl einfach zu viele Daten für rsnapshot?
Ich denke ich hab die Lösung gefunden – die Partition auf der USB-Platte hatte wohl einen Schuss. Warum auch immer.
Seitdem ich diese mit gparted gelöscht und komplett neu erstellt habe, rennt die Platte wie sie soll.
Hallo Niko,
vielen Dank für diese ausführliche Anleitung, welche mich erst so richtig darauf gebracht hat ein System in dieser Art selbst aufzusetzen.
Ich würde aber gerne eine Sache etwas anders machen:
Ich betreibe derzeit bereits eine NextCloud auf einem externen Server mit guter Anbindung. Eine NextCloud daheim zu installieren scheitert im Moment an der entsprechenden Geschwindigkeit (nur 16 Mbit DSL verfügbar, von dem max. 10MBit im DL erreicht werden; Upload entsprechend schlechter)
Idee war nun also die Daten im Heimnetz via Netzlaufwerk abzulegen und vom NAS-System auf die existierende NextCloud zu syncen, d.h. auf der NAS den NextCloud Client laufen zu lassen.
– Funktioniert das so wie von mir gedacht?
– Hast du hierzu Erfahrungen / Tipps?
– Klappt das mit Ubuntu Server? (Konfiguration des Clients, etc.)
Ich hab schon ein wenig Erfahrung im Umgang mit Linux, würde mich da aber nicht als Experten bezeichnen…
Ich würde mich über eine Antwort bzw. ein paar Tipps sehr freuen!
Hallo Andi,
ich habe ein ähnliches Setup auch eine Zeit lang eingesetzt. Du kannst den Nextcloudclient auch über die Kommandozeile nutzen, mit dem Befehl nextcloudcmd. In der Hilfe von Nextcloud https://docs.nextcloud.com/desktop/2.3/advancedusage.html findest du unter der Überschrift „Nextcloud Command Line Client“ die entsprechenden Befehle.
Allerdings führt nextcloudcmd nur einmal einen Sync durch und beendet sich dann wieder. Du musst den Befehl also beispielsweise über einen Cronjob in regelmäßigen Abständen ausführen.
Hey!
Sehr gutes Tutorial, jedoch habe ich eine Frage: Reicht die Performance des CPU’s, wenn man eine Cloud, einen Vault (Bitwarden) und mehrere WordPress-Seiten hosten will?
Mfg
Hallo,
das kann ich dir leider nicht sinnvoll beantworten. Gerade bei Nextcloud und WordPress kommt es ja darauf an, wie intensiv die Dienste genutzt werden.
Hallo Niko,
vielen Dank für das Tutorial. Läuft alles bestens, mein einziges Problem war das Paket usbmount. Aber nur, weil ich die Kommentare nicht ganz zu Ende gelesen habe … 😐
Vorhin habe die schon im Mai von JK genannte Seite selbst gefunden, schnell neu installiert und schon klappt alles. Nochmals vielen Dank für die super Arbeit.
Viele Grüße
Moin, das Tutorial ist top hat uns gut geholfen.
allerdings haben wir bei rsnapshot ein error wenn wir
sudo rsnapshot configtest
ausführen.
dies ist die meldung die kommt habe alles mit tab getrennt statt spaces daran liegt es also nicht.
vielleicht kannst du da ja weiter helfen.
—————————————————————————-
rsnapshot encountered an error! The program was invoked with these options:
/usr/bin/rsnapshot configtest
—————————————————————————-
ERROR: /etc/rsnapshot.conf on line 98:
ERROR: retain daily 7
ERROR: ———————————————————————
ERROR: Errors were found in /etc/rsnapshot.conf,
ERROR: rsnapshot can not continue. If you think an entry looks right, make
ERROR: sure you don’t have spaces where only tabs should be.
LG
Florian
Hi Florian,
wie hattest Du Dein Problem gelöst? Ich habe das gleiche. der Tab wird nicht als Tab erkannt, egal wie oft ich die Eingabe wiederhole
HG Joon
Hi,
könntest Du diesem Setup noch die Installation von PI-Hole hinzufügen. Wäre für ein 24/7 System noch ein zusätzliches super Feature.
Gruß
Madcowcamper
Hallo Madcowcamper,
Pi-hole ist ein tolles Projekt. Ich setze Pi-Hole selbst auf einem Raspberry Pi Zero ein, allerdings nur für bestimmte „IOT“-Geräte wie z.B. den Amazon FireTV. Wer seiner Familie oder seinen MitbewohnerInnen plötzlich einen Pi-Hole im Netzwerk unterjubelt, muss sich sicher einige Fragen gefallen lassen. Warum bestimmte Webseiten nicht mehr aufgerufen werden können oder nicht richtig laden, Google-Anzeigen nicht mehr angeklickt werden können, bestimmte Links aus der Twitter-App nicht mehr funktionieren…
Ich wollte die Artikelreihe bewusst anfängerfreundlich gestalten und da passt Pi-Hole dann meiner Meinung nach nicht so gut.
Gruß
Niko
Hallo Niko,
ich habe heute den Rechner soweit aufgesetzt, dank deiner Anleitung hat auch fast alles auf Anhieb geklappt.
Probleme hatte ich nur beim Netzwerk, das konnte ich aber dank der folgenden Anleitung lösen:
https://www.thomas-krenn.com/de/wiki/Netzwerk-Konfiguration_Ubuntu_-_Netplan
Was mich aber derzeit noch ein wenig irritiert:
Ich höre, dass die ganze Zeit auf den Festplatten gearbeitet wird, obwohl noch nichts synchronisiert wird o.ä.
Das typische Zugriffsgeräusch der Platten eben. Verbaut sind zwei 8TB WD red.
Hast du dafür eine Erklärung? Muss ich noch etwas einstellen?
Danke und viele Grüße,
Andi
Hallo Niko,
noch als Ergänzung:
Ich hatte den Rechner jetzt einmal einige Stunden laufen, die Zugriffe bleiben bestehen. Die Platten werden auch nicht in einen Ruhezustand geschickt, d.h. sie laufen durchgehend.
Der Stromverbrauch liegt dabei auch bei durchgehend ca. 30Watt, ich denke neben der Haltbarkeit der Festplatten könnte sich das hier auch noch positiv auswirken.
Ich wäre also weiterhin für Ideen dankbar…
Viele Grüße,
Andi
Hallo Andi,
Standardmäßig gehen die Festplatten nicht in Standby. Das musst du erst konfigurieren, z.B. mit hdparm.
Bist du sicher dass dein Raid vollständig synchronisiert ist? Mit
sudo mdadm --detail /dev/md0kannst du das prüfen.Wenn du frisch formatiert hast kann es auch sein dass das System die Inode-Tabelle noch initialisiert. Damit das Formatieren schneller geht, wird das nachträglich gemacht. Bei 8TB kann das durchaus einen kompletten Tag dauern.
Mit
iotopkannst du nachsehen welcher Prozess die Lese-/Schreibvorgänge verursacht, musst du wahrscheinlich mitsudo apt install iotopvorher installieren. Wenn es an der Inode-Tabelle liegt, ist wahrscheinlich der Prozess jbd2 der Verursachern. Dann hilft nur warten.Gruß
Niko
Hallo Niko,
Dank Deines Buches läuft mein Server mit vergleichbarer Hardware wie empfohlen wunderbar. Im Moment überlege ich, Nextcloud auf einen vServer (z.B. bei Netcup) auszulagern. Kann ich dabei eigentlich von einem spürbaren Geschwindigkeitsvorteil ausgehen?
LG Peter
Hallo Peter,
ich habe bis vor kurzem eine Nextcloud auf einem Netcup RS 1000 G8 (320GB Festplatte) betrieben. Da ich mich aber nicht mehr um den Server kümmern wollte bin ich zur gemanagten Nextcloud bei Hetzner umgezogen.Ich hatte auch die Tuningtipps von https://docs.nextcloud.com/server/17/admin_manual/installation/server_tuning.html umgesetzt, insbesondere OPCache und Redis. Die Performance ist auf jeden Fall hervorragend und die Verbindung natürlich zuverlässiger als am DSL zu Hause.
Gruß Niko
Hallo Niko
Dank deiner tollen Anleitung läuft mein Server nun mit Nextcloud und qbittorrent. Auch die Samba Freigabe funktioniert.
Eine Frage hätte ich noch zu Nextcloud:
Dort gibt es ja den Punkt „E-Mail Server konfigurieren. Ich habe also lediglich E-Mail Adressen von GMX und apple. Bei Strato habe ich auch eine Domain mit dem günstigsten Paket (ohne DynDNS) registriert, bei dem ich auch E-Mail Adressen habe. Kann ich davon etwas nutzen oder muss dafür ein Mailserver auf dem jetzt installierten ubuntu laufen?
Jetzt wollte ich mich um ein Backup kümmern. Ich möchte aber nicht die Daten in der Cloud sichern, sondern das System. Wenn ich also das ein oder andere teste und mir dabei das System „zerstöre“ (während der Installation 2 mal passiert, was immer eine komplette Neuinstallation nach sich zog) möchte ich einfach das Backup einspielen und der Stand „JETZT“ ist wieder hergestellt.
Ich vermute mal die Berschreibung von diesem Teil 7 ist eher zum Sichern der Daten in der Cloud gedacht.
Auf jeden Fall vielen Dank für diese Anleitung!!!
Roland
Freut mich, dass alles funktioniert.
Klar kannst du deine Emailadressen benutzen. Du musst in Nextcloud den Sendemodus, in den E-Mail-Server-Einstellungen, auf SMTP stellen und z.B. die GMX-Server eintragen. Die Daten findest du unter https://hilfe.gmx.net/pop-imap/pop3/serverdaten.html. Dann verwendet Nextcloud den GMX-Server zum Versenden von Emails.
Leider kenne ich keine Möglichkeit das komplette System im laufenden Betrieb zu sichern. Jedenfalls nicht mit dem verwendeten Dateisystem Ext4. BTRFS (und ZFS) können Snapshots im laufenden Betrieb erzeugen, das ist aber kein Thema für ein einsteigerfreundliches Tutorial. Insbesondere weil Ubuntu von Haus aus die Verwendung dieser Dateisysteme für das Root-Dateisystem nicht vorsieht.
Wenn du eine externe Festplatte hast die du sonst nicht brauchst, könntest du aber beispielsweise mit Clonezilla ein Image deiner Systemplatte sichern. Clonezilla bootest du von einem USB-Stick und kannst dann ein Abbild eines Datenträgers auf einen anderen Datenträger sichern. Wenn das System defekt ist, kannst du das Image wieder zurück spielen. Eine einfache Ein-Klick-Lösung ist das aber auch nicht.
Gruß
Niko
Ah, sorry, ich hatte da mit dem Mail Server weitaus komplizierter gedacht…
Danke! Funktioniert!
Mit dem Backup hatte ich schon dran gedacht, es so zu machen, wie ich es oft mit meinen Windowssystemen mache – mit Trueimage, oder in dem Fall evtl. besser mit Clonzilla – ein Image der Systemplatte erstellen. Ich habe hier noch ein paar leinere 34-40 GB Platten liegen, die ich dafür nutzen kann.
Nochmals Danke! Bin jetzt richtig happy, dass ich das so hinbekommen hab!!!
Gruß
Roland
Hallo Niko,
vielen Dank für Dein hilfreiches Tutorial. Damit konnten wir unserem HP Proliant N36 (Gen1 – kein Scherz) – wieder Leben einhauchen.
Alles hat auf Anhieb funktioniert.
Zum Thema Backup habe ich noch eine Frage:
Muss die MariaDB zum sichern gestoppt werden und falls ja, wie – oder ist das nicht erforderlich?
Ist hier die Wahl des Sicherungstools relevant? Duplicati oder Rsnapshot
Gruß aus Malta
Hallo Niko,
habe das jetzt mit einem MariaDB dump lösen können.
Der Dump wird 10 Minuten vor der Duplicati sicherung gemacht.
Alle 14 Tage wird dann via Cron alles was älter ist als 14 Tage automatisch gekillt. Soweit der Plan!
Dank nochmals für diese klasse Anleitung.
Malta ist eine Reise wert…
moin niko 🙂
erstmal vielen lieben dank für diese anleitung. hat nach mehreren anläufen dann auch endlich geklappt. warum ? nun, deine anleitung ist schon etwas älter, mittlerweile gibts 18.04.4 und da hatte ich probleme mit dem netzwerk und der nicht vorhandenen schnittstelle nach reboot. ich bin dann bei 19.04 gelandet und habe das dann testweise durchexerziert. ein wenig ratlos war ich bei plex und der anmeldung. (es ist schon spät…)
eine idee hätte ich dann auch noch, um vielleicht ein wenig platz auf der externen backup-platte zu sparen. da die dateien ja eh kopiert werden, warum nicht noch packen ? (und den ordner dann löschen)
Hallo Nico
Danke für die gute Anleitung
Läuft seit etwa einem Jahr problemlos.
Zur Sicherung nutze ich Dublicati
da ich nicht ständig nachsehe ob alles klappt musste ich jetzt feststellen, dass seit dem 30.10.2019 keine Sicherung mehr erfolgte.
Als Fehlermeldung kommt Folgendes:
Unexpected difference in fileset version 8: 08.11.2019 12:00:01
(database id: 172), found 155488 entries, but expected 155489
Es scheint ein Datensatz zu fehlen.
Kannst Du damit etwas anfangen?
Eine neu eingerichtete Sicherung klappt wieder
Die alte Sicherung ist noch vorhanden.
Gruß
Christian
Hallo Christian,
mir ist so etwas auch schon passiert, als der Backupvorgang unterbrochen wurde (Stromausfall/Wegfall der Internetverbindung). Ich musste dann die lokale Datenbank von Duplicati neu erstellen lassen, was viele Stunden gedauert hat. Die alten Backups waren aber noch funktionsfähig und die Daten mussten auch nicht neu hochgeladen werden. Ganz perfekt ist Duplicati wohl noch nicht.
Gruß
Niko
Das es durch einen Stromausfall kommt?
Werde die Backup Zeit auf 01:00 Uhr stellen.
So ist der mögliche Stromausfall nicht hausgemacht.
Gestern hab ich die Nextcloud auf einen Raspberry Pi 4 realisiert.
Konnte es nicht richtig testen, da nur ein System im gleichen Netzwerk klappt.
Kennst Du eine Lösung, wie man es mit geänderten Ports so konfigurieren kann, dass beide gleichzeitig funktionieren?
Habe viel gelesen und alles mögliche probiert.
Kommen noch nicht mal auf die Startseite.
Wenn ich in der Fritz.Box die Ports auf die andere umschalte dann klappt die zweite.
Gruß
Christian
Hallo Niko,
bei mir läuft der Serve soweit auch. Ich habe allerdings keinen RAID-Verbund installiert sondern nutze nur eine Daten-HDD, daher ist das Backup für mich wichtig. Ich möchte hierfür eine zweite Platte in meinen HTPC einbauen und hier einen FTP-Server laufen lassen auf welchem ich regelmäßig ein Backup ablege (Alles im LAN zu Hause).
Herausforderung: Ich starte den HTPC ein – zwei mal am Tag, um Netflix zu streamen o.ä. Der FTP-Server läuft also NICHT 24/7. Gibt es eine Lösung, bei der die Backups immer dann durchgeführt werden wenn mein HTPC an ist? Ich möchte vermeiden dass Duplicati 22 Stunden am Tag versucht sich mit dem FTP-Server zu connecten, während dieser aus ist. Wenn ich mal in den Urlaub fahre ist der HTPC auch mal länger aus. Dass meine BackUps dann entsprechend alt sind, würde ich in Kauf nehmen.
Hallo Florian,
das kannst du schon machen, das Stichwort hierfür ist Pull-Backup. D.h. eine Backupsoftware läuft auf deinem HTPC und nicht auf dem Homeserver und zieht sich quasi das Backup vom Homeserver.
Allerdings sind Duplicati oder Rsnapshot dafür nicht geeignet. Du kannst sowas aber mit Rsync und einem Skript wie https://wiki.ubuntuusers.de/Skripte/Backup_mit_RSYNC/ umsetzen.
Der HTPC braucht dafür Passwortlosen SSH-Zugang auf den Homeserver via Public-/Private-Key (https://www.techgrube.de/tutorials/ssh-login-mit-public-private-key-authentifizierung).
Auch BorgBackup (https://borgbackup.readthedocs.io/en/master/deployment/pull-backup.html) kann Pull-Backups.
Hallo Niko, danke für die schnelle Antwort. Auf meinem HTPC läuft Windows 10, daher bin ich mir unsicher wie ich dort das Pull-Backup einrichte für meinen Ubuntu-Server. Hast du da noch einen Tipp für mich? Danke im voraus.
Hi Niko,
ich habe das gleiche Problem wie Florian (22.Sept. 19). Der erste Tab wird nicht erkannt. Es ist egal, ob mit oder ohne Tab, ich hab als Test auch ein „#“ vor die Zeile gesetzt, dann wird eben die nächste nicht erkannt. Ein weiterer Test: eine Zeile freilassen:
#retain hourly 6
#
retain daily 7
auch so wird „retain daily 7“ nicht erkannt.
Schmeiße ich alle Zeilen, die mit „#“ starten raus, wird wieder die 1.Zeile nicht erkannt…
Ich bin inzwischen ziemlich ratlos…der erste Tab wird einfach nie erkannt…Wie lässt sich das Problem lösen?
Herzliche Grüße Joon
PS.: ich kann mich ansonsten übrigens nur einreihen. Das Tutorial ist großartig und funktioniert super im Großen und Ganzen.
Hi Niko, hi Florian,
nachdem ich nun sehr viel rumprobiert habe: das einzige, was geholfen hat, war, die ganze .conf zu löschen und alles neu rein zu setzen…. und immer schön auf die Tabs achten 😉
HG Joon
Hallo Niko
Habe mich noch mal mit Duplicati beschäftigt.
Den Fehler in der Sicherung konnte ich beseitigen, die Daten blieben erhalten
Habe unter Profis: Datenbank: Wieder herstellen (löschen und reparieren) ausgeführt.
Das hat einige Zeit gedauert.
Seit dem läuft alles wieder wie gewohnt.
Alle alten Sicherungen sind noch vorhanden.
Weißt Du, wie man eine Fehlermeldung erhalten kann, ohne Duplicati aufzurufen?
Gruß
Christian
Hallo Christian,
man kann Duplicati sagen, dass es Benachrichtigungen per E-Mail verschicken soll. Das habe ich aber nie getestet.
In den Einstellungen unter „Optionen für Profis“ muss man ein E-MAil-Konto hinzufügen (SMTP-Server, Username, Passwort) und eine Regel, wann E-MAils verschickt werden sollen.
Aber, wie gesagt, habe ich selbst noch nicht verwendet.
Gruß
Niko
Hallo Nico,
ich habe eine Frage. Lässt sich die Anleitung so auch mit Debian realisieren?
Gruß
Madcowcamper
Ich denke schon, habe es aber nicht selbst getestet.